![]()
![]()
2024/10/30governance


AI Ethics and Company Regulations
Author:CISO Service Division Kazuyuki Nakamura

In light of the recent accelerated use of AI by companies, we have reviewed ethical regulations regarding copyright etc., how to utilize these within companies, and issues to be addressed by companies when promoting AI use.
Regarding the use of AI, opinions that a certain number of jobs will be taken away from human workers are rife, and there are numerous discussions about the risk of copyright infringement caused by generative AI. On the other hand, it seems that recently we have heard less about the possibility of machines surpassing human intelligence, such as the discourse around the theory of "singularity". We are currently at a major turning point in technology, and we need to discuss how to deal with AI in a positive way when it comes to corporate activities (that is, business). What kinds of internal regulations and general ethical standards should be followed? While such issues urge discussion, I somehow feel that the necessary attention to them has been decreasing. However, just because we have fewer opportunities to hear about them does not mean that the discussion itself has disappeared. Since the now rather distant past when the word "AI" first entered public discourse, discussions about the ethics and copyright issues related to AI (in terms of LLMs, or "large language models") have continued. First of all, I would like to understand the trend and, in writing this article, hope to offer some help in changing perspectives on how AI can be positively integrated into society and used for safe business practices.
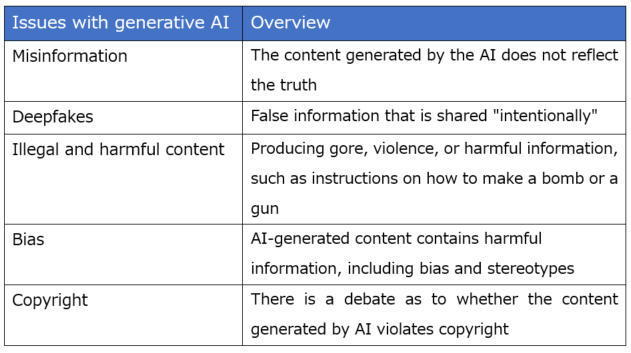
First of all, what are the risks that have become evident with the emergence of AI? Commonly cited issues include "misinformation, deep fakes, illegal and harmful content, bias, and copyright."
Table 1. Five Main Challenges in Generative AI
Source: Based on "Responsible AI and Rules" by Naosuke Furukawa and Kyoko
Yoshinaga (First edition published May 15, 2024)
Closed networks were connected, open networks were established, and the digital ocean known as the Internet was created, into which miscellaneous digital data of unknown authenticity was thrown. With the founding of Google in 1998, an efficient search engine presented the world with a way to use the digital ocean efficiently, and with the release of generative AI, users gained the ability to employ this ocean of data as if it were driven by a single will. At the same time, misinformation, deep fakes, and illegal and harmful content were easily and efficiently created, and a wide variety of biases and ethical issues regarding copyright have resulted in worldwide chaos.
These problems will not be solved even if a major technological shift takes place. This is because the essence of the problem lies not in the technology but in we humans who are the users of it. This, furthermore, is because the laws derived from the ethical perspective can no longer accommodate current changes and mutations.
However, when it comes to copyright, I think there will continue to be substantial discussion regarding the assertion that "if a work happens to be similar to someone else's work without our knowledge, it does not constitute copyright infringement." This is because copyright issues regarding AI are almost all about one point: reliability. So, let's briefly touch on the issue of reliability and how AI should be involved. I think that in the future, when AI becomes recognized as a useful in-house tool and its use accelerates, various discussions are bound to arise. In other words, what happens when you intentionally make AI read learning data, or when you intentionally make it read specific data to get closer to a specific output?
So, what measures can businesses take to avoid infringing copyright? In the unlikely event that copyright infringement does occur, what measures will be imposed? Let's briefly touch on these.
Source: Based on "On the Concept of AI and Copyright (Draft)" by the Legal System Subcommittee of the Copyright Subcommittee of the Council for Cultural Affairs (First Edition (Draft) published on February 29, 2024)
In the "proviso" of Article 30-4 of the law, it is stipulated that "[t]his does not apply if it would unduly harm the interests of the copyright holder in light of the type and use of the work and the manner of use." In this case, the article does not apply.
Measures that can be taken by businesses that conduct AI learning when copyright infringement occurs during AI learning.
① If Article 30-4 of the Law does not apply because of the coexistence of the purpose of enjoyment or because it falls under the proviso, and other rights restriction provisions do not apply either, copying for AI learning constitutes copyright infringement unless permission is obtained from the rights holder.
② In this case, the measures that can be taken by those who have made copies for AI learning include claims for damages (Civil Code Article 709), injunctive relief (claims for the cessation or prevention of infringing acts (Civil Code Article 112, Paragraph 1)), claims for measures necessary to cessation or prevention of infringement (Civil Code Article 112, Paragraph 2), and criminal penalties (Civil Code Article 119).
③ Note that a claim for damages requires the existence of intent or negligence, and a criminal penalty requires the existence of intent.
Some people may think that this is just a "proviso," but it is extremely difficult to clarify all the reference data used in AI. In the future, it may be possible to create greater efficiency with new technology, but this is a long way off.
In the future, I do think that there will be more cases within companies where data that has been organized and processed through AI training and learning is read by AI for custom purposes. Therefore, if we focus only on the convenience of the AI engine (that is, the program function) and neglect to discern the data to be read, it will cause various problems later on, and there is a high possibility that the ethics and copyrights that have been built up thus far will be neglected. No matter how firmly internal regulations are established, it may be difficult to regulate and monitor this point. In fact, it may be necessary to review the Japanese education system itself and proceed with some determination to rebuild everything, including copyright law, in order to accommodate the digital world in anticipation of the coming of AGI (Artificial General Intelligence), an era in the near future when AI will surpass human wisdom in omniscience and omnipotence. This will be on the scale of both the country and the people.
However, at present, it is called "generative AI," and while it functions well at generating text, it does not have emotions, thoughts, or a sense of self. Moreover, even if it can be used for daily decision-making, it is not capable of making independent decisions.
The country is also slowly getting its act together and focusing on education reform to accept edtech, ICT education, and the current changes and transformations. GIGA Schools are one example of this. As a result, I have the sense that by transitioning to an education system based on the Internet (that is open network), the problems and issues that arise within it will gradually be sorted out, and we will have no choice but to wait for the digital space to be reborn as a step-up in terms of ethics for the next generation of children. Too, it may well be necessary to develop and evolve the concept of "social acceptability" which is often used as a criterion for judgment in the legal profession.
中村 和之(なかむら かずゆき)

2024年にデジタルアーツコンサルティング株式会社(DAC)
※2024/4よりアイディルートコンサルティング株式会社(IDR-C)へ社名変更
ヒューレットパッカード、パロアルトネットワークスを経て、ITインフラ・サイバーセキュリティの分野においてコンサルタントとして活動。最近では、多岐に渡るセキュリティ製品を顧客要件に応じて適切に組み合わせる知験作りにフォーカスした活動に注力しています。
Elizabeth Tinsley エリザベス ティンスリー(英文/スピーキング)

カリフォルニア大学 アーバイン校 仏教文化史 助教授
(University of Cambridgeにて学位取得)
https://elizabethtinsley.com/about/
アカデミックな経歴をベースに、欧州や米国、日本と日本の歴史文学・文化,芸術を新たな視点で紐解き、広める活動を行っています。
